-
[DL][Windows11] YOLOv3 물체 검출 학습ML(머신 러닝)/Windows 2023. 9. 22. 02:16
1달 반 열심히 구르다 온 주인장입니다. 연구 자료 날아간게 화나서 밤샘 도중 블로그로 일탈하려합니다.
오늘의 주제는 딥러닝을 하는 사람들이라면 한번씩 해보는 3대장 CNN, RNN, YOLO 중 YOLOv3에 대한 내용입니다.
YOLO 버전은 상당히 많은데 3을 사용한 이유는 제가 한참 딥러닝을 공부할 때는 v5까지 나왔을 때라 v3를 기준으로 했습니다.
(v5까지 있었는데 v3을 사용한 이유는 아래에서 서술)
0. YOLO의 역사와 버전
궁금하지 않으시면 스킵하셔도 됩니다만, 알아두시면 좋습니다.
간략하게 작성했습니다.
자세한 내용은 논문과 제작자들의 사이트를 통해 알아보실 수 있습니다.
- YOLO v1 : 2016년 최초 발표, 실시간 객체 검출에 적합.
S x S 크기의 그리드 셸(Grid Cell)을 통해 Input Image를 분리, Cell 마다 Bouding Boxes를 생성하여 Class를 예측 - YOLO v2 : 2017년 발표
기존 Darknet을 개선한 Darknet 19를 적용함.
v1의 마지막 Fully Connected layer를 삭제하고 1x1의 Convolution Layer를 추가함.
Anchor Box의 도입
Fine-Grained Features 도입 등 - YOLO v3 : 2018년 발표
v2 대비 속도는 줄었으나 성능 향상을 이루었으며, Darknet 53으로 변경
Multilabel Classification 도입 (중요 - 하나의 박스 안에 여러 객체 탐지가 가능해짐) - YOLO v4 : 2020년 발표
v3까지는 작은 물체 탐지에 취약한 특징을 가졌으나, v4에서는 input 해상도를 높이고, layer 수를 늘려 이를 해결하려고 시도함. - YOLO v5 : 2020년 발표
v5는 총 4가지 모델을 가지고 있는데, depth multiple과 width multiple를 기준으로 크기별로 s, m, l, x 사이즈로 나눔 - YOLO v6 : 2022년 발표
v6은 Anchor-Free 모델로 공개됨
RepBlocks으로 강화한 PAN인 RepPAN을 사용 - YOLO v7 : 2022년 발표
여러개의 레이어가 학습하고 해당 레이어를 하나의 레이어로 접목시키는 모델을 사용 - YOLO v8 : 2023년 발표
C2f 모듈로 교체, ConvBottleneck 사이즈 변경, objectness 분기 삭제 등
크게 8가지 버전이 있네요. 이중 현재도 많이 사용되는 버전은 3, 5, 8입니다.
3은 한국어로 작성된 블로그 및 정리본이 많고, YOLO의 첫 제안자이자 제작자인 Joseph Redmon의 마지막 버전이라 그렇습니다.
Joseph Redmon은 YOLO를 개발하고 업데이트 하던 중, 인공지능과 객체인식 기술을 통해 생기게될 여러 이유로 연구 중단을 선언했는데요. 관련된 영상이 유튜브에 있으니 한번 보시는것도 좋겠네요.
5는 오픈 소스로 운영되고 최근까지도 업데이트가 되고 있어서 많이들 사용하고 있습니다.8은 가장 최신버전으로 통합 프레임워크로 구축되어, 여러 프로젝트에 접목하기 용이합니다.
제가 처음 YOLO를 접할 때는 객체 인식에 대해 연구 중일 때였습니다. 당시 YOLO와 LSTM, RNN에 대해 고민 중이였는데, YOLO의 설계 목적에 빠져 YOLO로 객체 인식에 대한 연구를 시작했습니다.
당시 최신 버전인 v5가 아닌 v3를 선택한 이유는 원작자가 YOLO를 설계 할 당시의 YOLO와 너무 달라져 YOLOv4, v5는 YOLO가 아니라고 생각 할 때 였습니다.물론 지금은 학술적으로 받아드리고, 여러 버전을 사용해봤지만 당시에는 Joseph Redmon에 상당히 빠져있었던것 같네요.
이 글을 읽으시는 분들은 YOLO를 첫 사용하시는 분들이 많을거라 생각됩니다. v3를 사용 후, 충분히 다른 버전에 대해서도 공부하시고 본인에 맞는 버전을 골라 사용하시길 바랍니다.
1. 환경 세팅
1) CUDA, CUDNN 설치
https://lonaru-burnout.tistory.com/16[ML][Windows 11] CUDA, cuDNN 설치
이 글은 NVIDIA 그래픽카드를 기준으로 작성되었음을 알립니다. 라데온 그래픽카드를 통한 머신러닝은 따로 다룰 예정입니다. 0. 자신의 GPU 확인 https://ko.wikipedia.org/wiki/CUDA CUDA - 위키백과, 우리 모
lonaru-burnout.tistory.com
2) jupyter lab 설치 or VScode 설치 (설치 안해도 됩니다. cmd로 실행 가능)
(둘 중 하나를 택해서 설치해주시면 됩니다. 실행 환경으로 사용합니다. 본문에서는 jupyter lab을 기준으로 설명합니다.)https://lonaru-burnout.tistory.com/17
[DL][Windows 11] 윈도우 텐서플로우 (TensorFlow) 설치
0. Python 우선 환경 설정을 위해 python이 필요합니다. 추후 가상환경을 만들어 구성할 예정이라, 버전은 3.x 버전 이상이라면 상관없습니다. # 수정합니다. 텐서플로우가 지원하는 파이썬 버전 확인
lonaru-burnout.tistory.com
3) openCV 설치
[Python이 설치 후 사용가능] pip install opencv-python pip install opencv-contrib-python [설치 확인] import cv2 print(cv2.__version__) -> 버전이 출력된다면 정상 설치 된겁니다.4. visual studio 설치 (15년도 이후 버전이여야 합니다.)
2. 데이터 모으기
데이터셋은 직접 모으는 것도 혹은 다운 받는 것도 괜찮습니다.
직접 YOLO용 데이터셋 만들기는 다음 포스트에서 설명드리겠습니다.본 글에서는 제가 수집했던 데이터를 사용하겠습니다.
추가) 커스텀 데이터 셋 만드는 방법에 대해 작성했습니다. 하단 링크를 참고 하시면 됩니다.
https://lonaru-burnout.tistory.com/21
[DL][Windows11] YOLOv3 커스텀 데이터셋 만들기
YOLOv3로 학습 및 검출에 대해 앞서 포스팅 했는데요. 포스팅에 사용된 데이터셋은 직접 수집하고 수정한 데이터셋입니다. YOLO용 데이터 셋 만들기에 대해 작성하며, 머신러닝에서의 데이터셋이
lonaru-burnout.tistory.com
3. darknet 다운로드
git 명령어가 사용가능 하다면 다음 명령어를 사용
git clone https://github.com/AlexeyAB/darknet일단 윈도우라면, 아래 링크에서 다운
https://github.com/AlexeyAB/darknet
GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Da
YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet ) - GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object ...
github.com
다운로드된 디렉토리를 작업 공간으로 옮겨주세요.
이전 포스터부터 사용되던 딥러닝용 디렉토리면 더 좋습니다.
4. darknet 세팅 및 설치
darknet-master\build\darknet 경로로 이동 한 뒤, darknet.sln을 visual studio로 실행해줍니다.
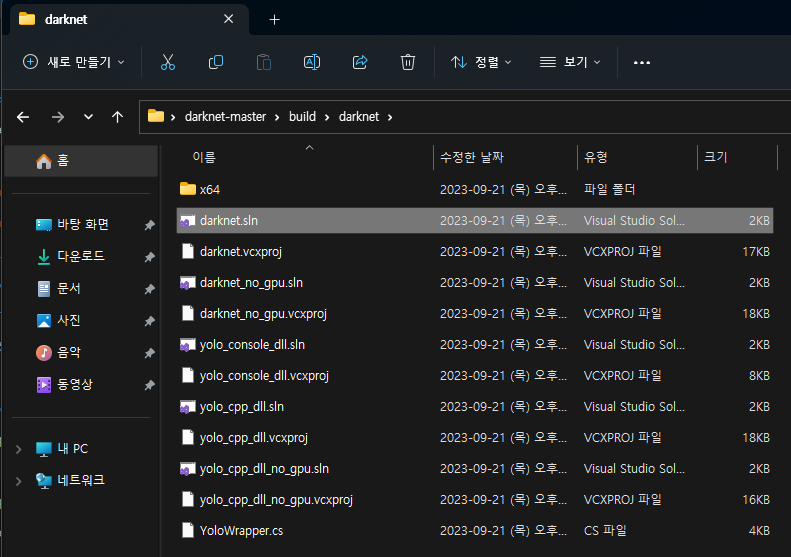
이후 Solution Explorer에 있는 darknet의 Build Dependencies(빌드 종속성) -> Build Customizations..(사용자 지정 빌드)을 선택합니다.

이후 버전에 맞는 CUDA를 선택합니다.
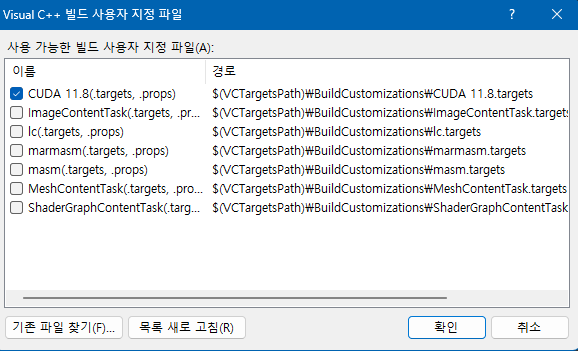
빌드를 위해 OpenCV와 CUDA, cuDNN을 사용해야하므로, 해당 경로를 설정해줘야합니다.
darknet 프로젝트를 우클릭하여 최하단 속성 탭을 선택합니다.
이후, 상단 구성을 Release, 플랫폼을 x64로 선택합니다.
아래 그림처럼 C/C++ -> 추가 포함 디렉터리(Additional include Directories)를 선택합니다.

openCV의 build\include 디렉토리와 CUDA, cuDNN이 설치된 디렉토리의 include 디렉토리를 포함시킵니다.

이후, CUDA C/C++ -> Code Generation에 본인의 그래픽 카드 CUDA Compute Capability를 확인하여 기입합니다.
확인방법은 https://developer.nvidia.com/cuda-gpus를 참고하시면 됩니다.
숫자가 7.5일 때 compute_75,sm75를 기입하시면 됩니다.
저는 그래픽 카드를 여러 개 사용 중이라 두 버전이 적혀있네요.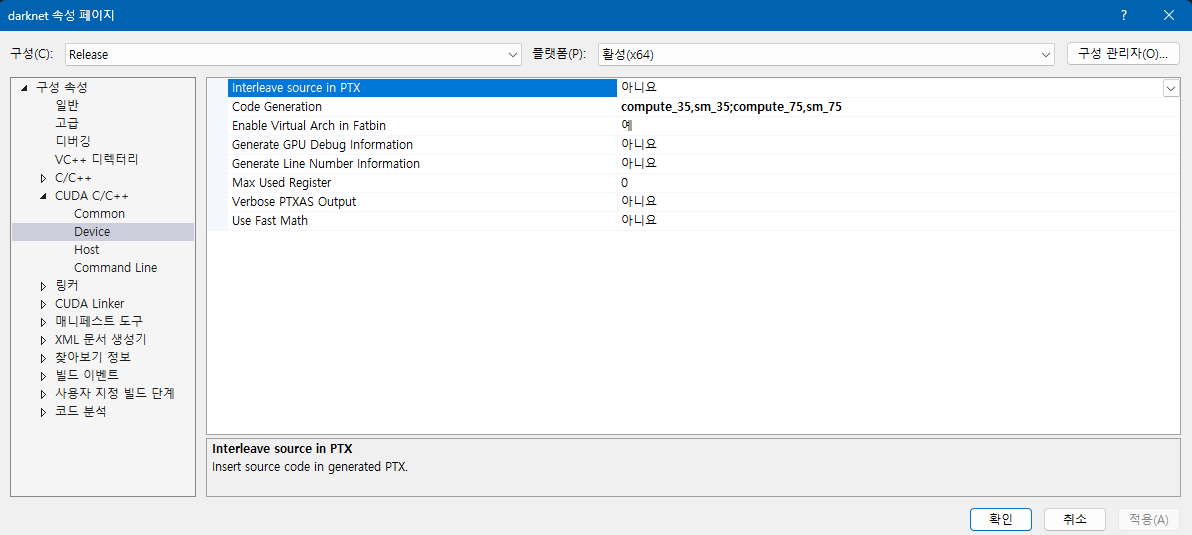
이후 Linker(링커) - General(일반) - additional Library Directories(추가 라이브러리 디렉터리)에 openCV의 lib 디렉토리 경로를 입력해줍니다.
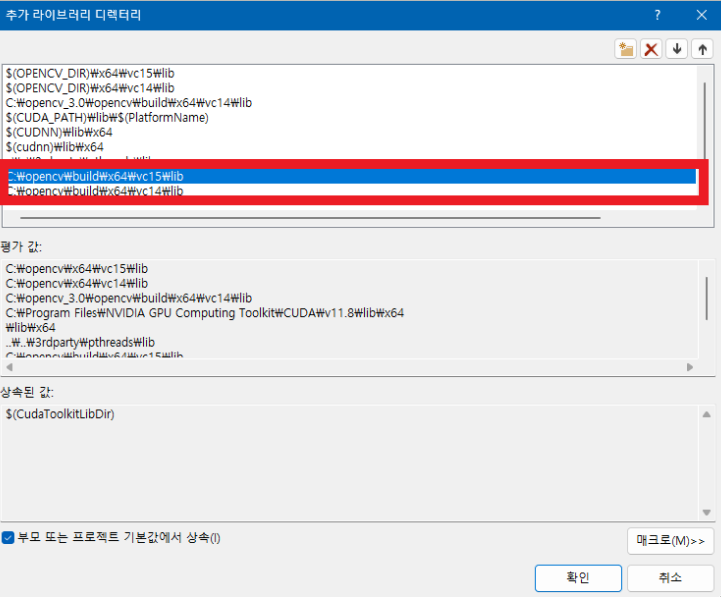
적용을 눌러주시고 마지막 단계입니다.
openCV가 설치된 디렉토리에서 Opencv_world숫자.dll, opencv_ffmpeg숫자.dll을 복사하여, darknet-master\build\darknet\x64로 복사해줍니다.
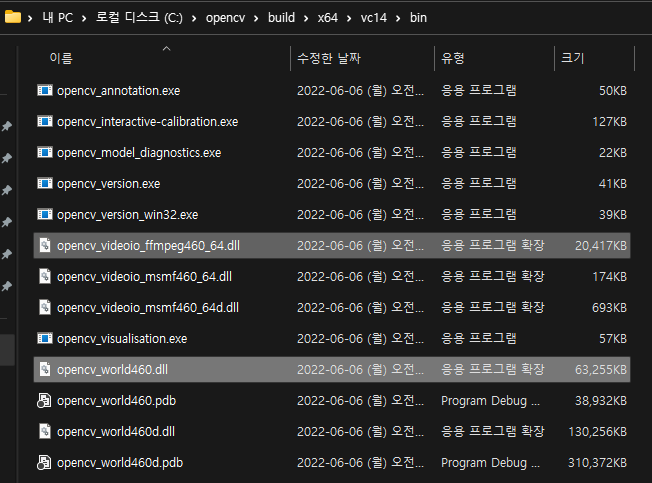
다 되었다면 우클릭을 하여 빌드해줍니다.

하단에 빌드 후 성공 1, 실패 0, 최신 0, 생략 0 이 떳다면 성공입니다.
5. 학습 시켜 가중치(weights) 만들기
우선 3가지 파일과 데이터 셋이 필요합니다.

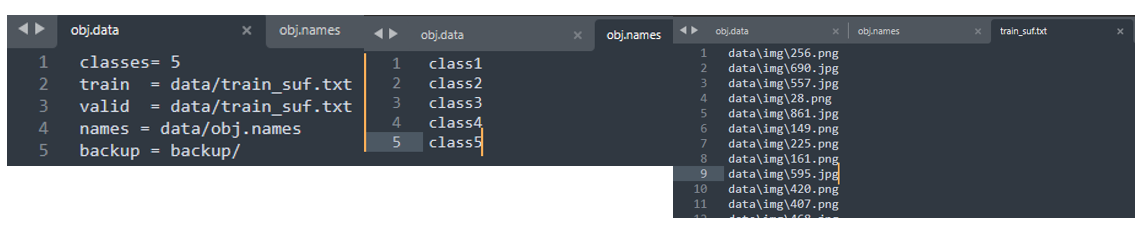
- obj.data : 분류할 class의 수, 학습 및 검증에 필요한 데이터셋을 불러올 경로, 객체(class) 이름을 저장한 파일을 불러올 경로, 도중에 멈췄을 때 backup시킬 디렉토리 경로를 저장합니다.
- obj.names : 학습 시킬 객체의 이름을 저장한 파일입니다.
- train.txt : 학습시킬 파일들을 저장한 파일입니다.
순서대로 obj.data, obj,names, train.txt 입니다. 해당 3파일은 위 2번 데이터셋 모으기 에서 다룹니다.
원래 학습과 검증은 6:4, 7:3 정도로 나누어 진행하거나 학습:검증:테스트를 7:2:1로 데이터를 나누어 넣어야합니다만, 여기서는 실습이 목적이므로 생략하도록 하겠습니다.
자세한건 데이터셋 만들기 편을 참고 하시면 좋겠습니다.
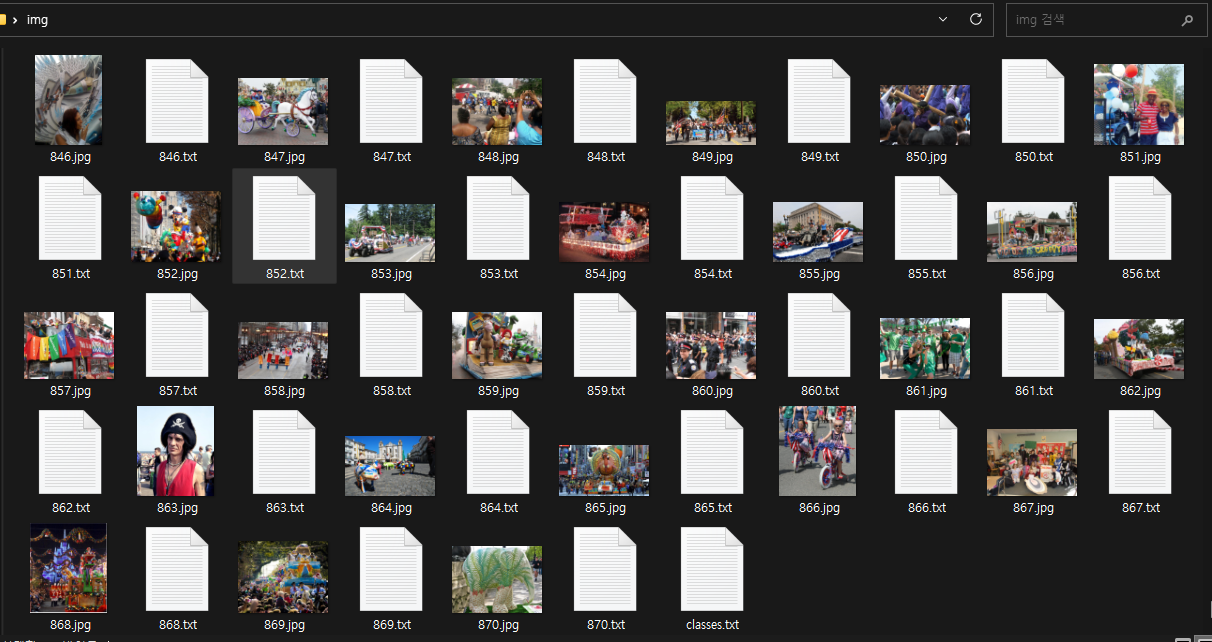
다음으로 데이터 셋입니다. 준비된 데이터셋의 디렉토리 명은 img으로 설정했습니다.
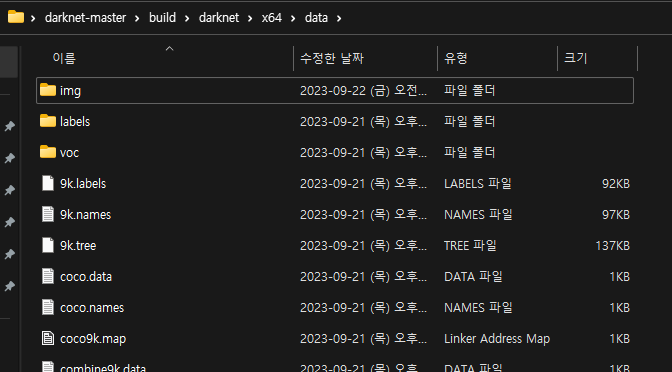
준비된 데이터셋 img 디렉토리와 obj.names, obj.data, train.txt를 다음과 같이 datknet-master\build\darknet\x64\data로 이동 시킵니다.
다음으로, yolo v3는 앞서 0장에서 말씀 드린것 처럼 darknet을 기반으로 만들어졌습니다.
darknet은 yolo에서 backbone으로 작동 되므로 darknet 파일이 필요합니다.
해당 파일은 다음 명령어를 통해 얻을 수 있습니다.
wget https://pjreddie.com/media/files/darknet53.conv.74혹은 다음 링크를 통해 받아주시면 됩니다.
https://pjreddie.com/media/files/darknet53.conv.74

해당 파일도 datknet-master\build\darknet\x64\data로 이동 시킵니다.
정말 거의 다 됐습니다. 마지막으로 yolov3를 실행하기 앞서 설정 파일을 건드려줘야합니다.
설정 파일은 datknet-master\build\darknet\x64\yolov3.cfg 파일입니다.
해당 파일을 열어 다음 몇 가지를 수정해야합니다.
1) batch : 사실 안건들여도 상관없는데 한번에 몇 장을 처리 할지 정하는 것입니다. 본인 pc 사양이 좋지 않을 경우 줄이시면 됩니다. 메모리 오류가 날 시 제일 먼저 줄이는 값중 하나입니다.
2) subdivisions : batch를 이 값으로 나누어 처리합니다. 적절히 수정하면 됩니다. 잘 모르겠다면 그냥 두셔도 무방합니다.
3) width와 height 입력되는 이미지 크기입니다.
4) learning_rate = 0.001 : 그래픽 카드 개수에 따라 값이 달라집니다.
ex) 1개 = 0.001, 2개 = 0.005, 4개 = 0.00255) classes : 검출할 객체의 수를 입력합니다. 앞서 만든 obj.data에 입력한 값으로 수정합니다.
6) filters : filter의 값은 (classes + 5) * 3 로 저장합니다. ex) classes가 5개라면 30으로 수정합니다.
7) max_batches : 학습 횟수를 의미합니다. class의 개수 * 4000 or class의 개수 * 4000 + 300 정도면 충분합니다.
8) steps : max_batches의 80% & 90%의 값으로 수정합니다.
9) anchors : darknet-master\build\darknet\x64 디렉로티로 이동하여 cmd를 실행시킵니다. 이후 아래 명령어를 실행해서 얻은 anchors 값으로 수정합니다. 이때, width와 height 값은 위에서 작성한 값으로 바꿉니다.
darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416주의)
아마 classes와 filters, anchors를 수정할 때, classes와 filters, anchors가 여러 개 일겁니다.
모두 수정하도록 합니다.아래는 anchors 값을 구하는 예시 입니다.
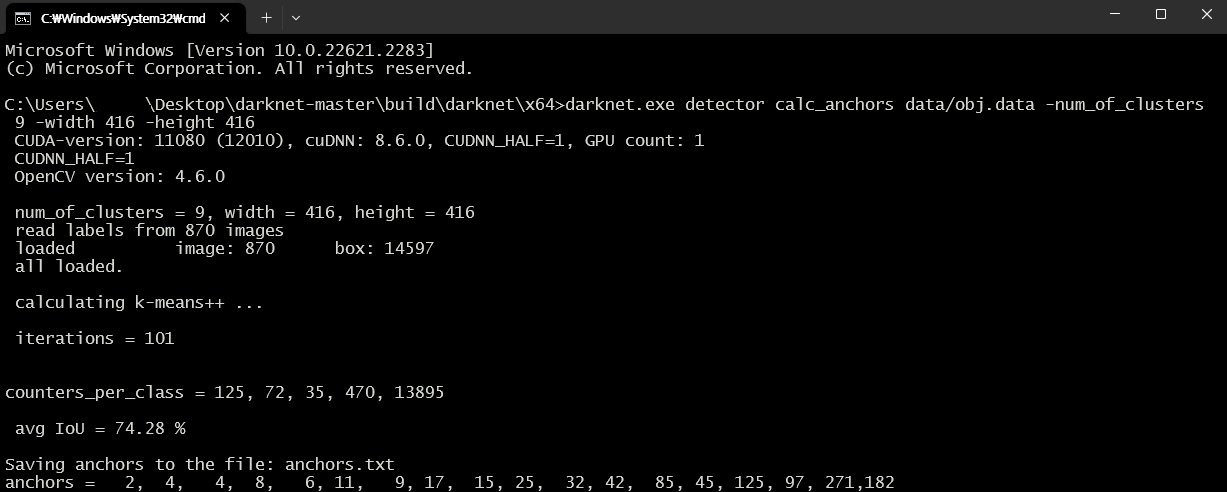
6. 학습 실행
anchors 값을 구했을 때 처럼, darknet-master\build\darknet\x64로 이동하여 cmd를 실행 합니다.
그 뒤, 아래 명령어를 실행합니다.
darknet detector train data/obj.data yolov3.cfg data/darknet53.conv.74 -gpu 0gpu가 1개 일때는 위 처럼 gpu 0옵션
gpu가 2개일 때, 두개 모두 사용은 -gpu 0,1
gpu가 2개 일때 2번 gpu만을 사용할 때는 -gpu 1
위 처럼 옵션을 입력하면 됩니다.
학습이 정상적으로 시작되면 다음과 같이 gpu 사용률이 오르며, 커맨드 창이 내려갈 겁니다.

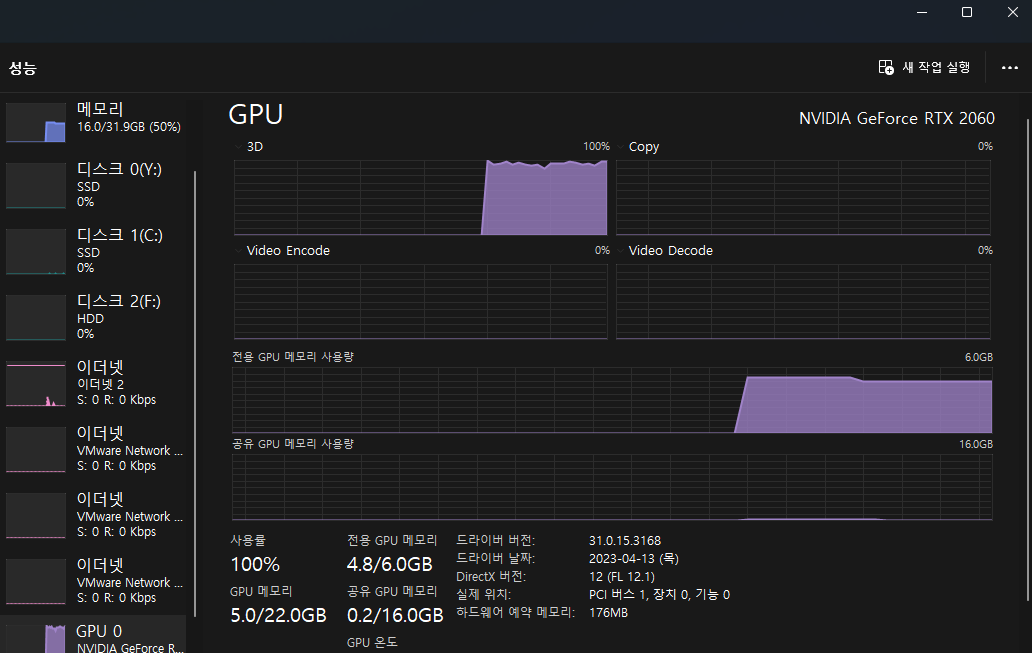
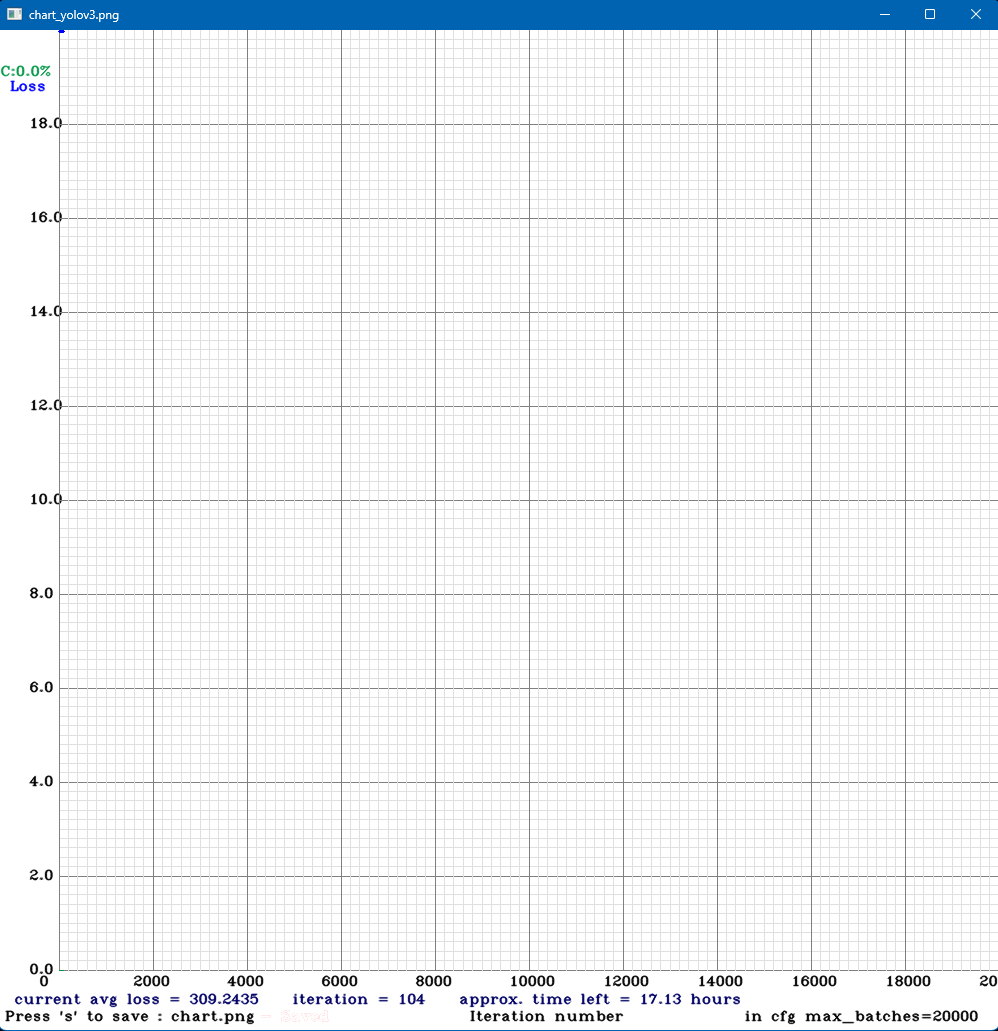
학습 중에 출력되는 차트 창은 s를 눌러 이미지를 저장 할 수 있습니다. 이미지는 darknet-master\build\darknet\x64\chart.png 혹은 chart_yolov3.png 입니다.
또한, 하단 approx. time left를 통해 예상 남은 시간을 확인 할 수 있습니다. 실제 학습에 필요한 시간과는 다를 수 있습니다.
제 경우 2시간 반 안되어 학습이 완료됐습니다.
다음 그림은 학습 도중 캡쳐한 차트입니다.

차트를 보시면 파란색 점이 보이는 해당 점은 loss로 원래는 선으로 이어져야하지만, 급격하게 떨어지는 값 때문에 점처럼 보이는 것 입니다.
학습이 진행 될 수록 loss가 줄어든다면 정상적으로 학습되고 있는 것 입니다.
7. 학습 도중 컴퓨터가 꺼졌거나 학습이 중단된 경우 다시 시작하는 방법
앞서 설명 중 피치 못하게 컴퓨터가 꺼진 경우 backup을 위한 디렉토리를 설정했습니다.
저희가 설정한 디렉토리는 darknet-master\build\darknet\x64\backup 으로
해당 위치로 가보시면 다음과 같이 yolov3_last.weights 파일이 생성되어 있을 겁니다.
해당 파일은 일정 주기마다 생성되는 학습 가중치로 최근 백업된 가중치 입니다.
저희는 이 가중치를 사용하여 학습을 마저 하도록 하겠습니다.
사용 방법은 다음과 같습니다.
앞서 학습을 시작하는 방법과 거의 동일합니다. darknet-master\build\darknet\x64\ 디렉토리에서 cmd를 실행합니다.
이후 다음 명령어를 입력합니다.
darknet detector train data/obj.data yolov3.cfg backup/yolo-obj_last.weights -gpu 0darknet 백본 대신 마지막으로 사용한 가중치를 사용하면 됩니다.
8. 검출
앞서 데이터셋 구축, 데이터 학습을 진행했으니 마지막 대망의 검출 테스트입니다.
테스트는 다음 명령어를 통해 진행 가능합니다.
명령어 중 backup/yolo-obj_last.weights 부분은 가중치를 불러오는 부분입니다. 서로 다른 데이터셋을 학습 할 때는 학습완료된 가중치를 따로 저장하거나 이름을 바꿔 저장하도록합니다.
data/1.jpg와 data/1.mp4 자리에는 검증할 데이터를 data 디렉토리로 저장하거나 혹은 data/검증자료.확장자 대신 절대 경로로 다른 위치의 검증 자료를 불러오도록 합니다.
1) 사진 내 물체 검증
darknet detector test data/obj.data yolo-obj.cfg backup/yolo-obj_last.weights data/1.jpg2) 영상 내 물체 검증
darknet detector demo data/obj.data yolo-obj.cfg backup/yolo-obj_last.weights data/1.mp43) 실시간 웹캠을 통해 물체 검증
darknet detector demo data/obj.data yolo-obj.cfg backup/yolo-obj_last.weights
9. 마치며
긴 글 읽어주셔서 감사합니다.
더보기중간 중간 설명을 곁들이다 보니 글이 길어졌네요.
단순히 명령어와 사진만 첨부하는 것이 아닌 제가 공부한 것을 정리 하는 목적으로 블로그를 운영하다 보니 길어집니다.주인장의 하소연도 점점 길어져요.. 대학원 입학 후, 시간이 잘 안나네요. 그래도 열심히 적어보겠습니다.
이전 블로그에서 작성한 포스팅도 이전해야하는데..
할.. 수 이겠... 죠..?
다음에도 좋은 글 쓰도록 노력해보겠습니다.
'ML(머신 러닝) > Windows' 카테고리의 다른 글
[DL][Windows] 윈도우 텐서플로우 (TensorFlow) GPU 인식 문제 (2) 2023.12.07 [DL][Windows11] YOLOv3 커스텀 데이터셋 만들기 (0) 2023.09.22 [DL][Windows 11] 윈도우 파이토치 (PyTorch) 설치 (0) 2023.06.07 [DL][Windows 11] 윈도우 텐서플로우 (TensorFlow) 설치 (0) 2023.06.02 [ML][Windows 11] CUDA, cuDNN 설치 (7) 2023.06.02 - YOLO v1 : 2016년 최초 발표, 실시간 객체 검출에 적합.