-
[ML][Windows] AMD gpu로 머신러닝을 해보자 (DirectML, TensorFlow, Pytorch)ML(머신 러닝)/Windows 2023. 12. 11. 00:46
0. AMD 그래픽드라이버 머신러닝 윈도우 지원
이전까지는 리눅스에서만 ROCm 머신러닝을 지원하였으나, 2023년 7월 27일 ROCm5.5 부터 윈도우 지원이 추가되었다.
따라서, ROCm을 사용하여 윈도우에서 머신러닝 구동이 가능하게 되었다.기존 우분투에서 세팅하여 사용하던 환경을 윈도우에 세팅하는 과정을 정리하였다.[Hardware Setting]
CPU : i7-1260P
Ram : 40G / DDR4
GPU : AMD Radeon RX 6700XT
OS : Windows 11 pro (23H2)
[수정]
ROCm이 윈도우를 지원하는 버전은 HIP SDK 5.5.1 부터이며, 공식 가이드에는 5.7.1까지 공식 문서가 있는것을 확인 할 수 있다. 다만, HIP SDK를 설치하려하면 왜인지 5.5 버전이 설치 되는데, 윈도우에서 네이티브하게 사용하는게 안된다..
그 외에도 Pytorch가 지원하는 ROCm의 최신 버전과 차이가 나서 윈도우에서 네이티브하게 돌리는 것은 23년 말 기준 불가능한 것 으로 확인 되었다.
제목을 보다 싶이 윈도우에서 돌리고 싶은 여러 이유가 있어 생각한 대안은 다음과 같다.
1) VMware를 통한 가상 환경에 리눅스를 올려 사용 : 성능 저하 심함
2) WSL 사용 : 그나마..?
3) MS에서 배포하는 DirectML 사용하기 : 윈도우 native 지원
주인장은 python 가상환경과 DirectML을 사용하였다.
1. 환경 세팅
DirectML를 사용하기 위한 사양은 아래와 같다.
https://learn.microsoft.com/ko-kr/windows/ai/directml/gpu-tensorflow-plugin

Windows native 사양 TensorFlow의 사양은 다음과 같다.
TensorFlow 2 사양 따라서 python은 3.7 ~ 3.9 사이의 버전을 사용해야한다.
우선 패키지 관리와 버전 관리를 위해 가상 환경을 만들도록 한다. anaconda, miniconda, venv 모두 가능
주인장은 Python3.9 버전과 python 기본 모듈인 venv를 사용하였다.
py -3.9 -m venv [가상환경이름] python3.9 -m venv [가상환경이름]가상환경을 만들기 위해서는 해당 버전의 python이 설치 되어있어야 한다.
가상환경 진입 후, tensorflow와 pytorch, DirectML을 설치한다.
.\가상환경디렉토리\Scripts\activate #가상환경 진입 #tensorflow + DML pip install tensorflow-cpu==2.10 pip install tensorflow-directml-plugin #pytorch + DML pip install torch torchvision torchaudio pip install torch-directml #번외 jupyter lab pip install jupyter lab jupyter lab #주피터 랩 실행윈도우 네이티브로 지원되는 tensorflow는 2.10이 마지막 버전이며, GPU를 지원하는 마지막 버전이기도 하다.
또한, DirectML은 Tensorflow 2.10 버전 만을 공식적으로 지원한다.
만약 실수로, tensorflow 혹은 tensorflow-gpu 버전을 다운 받았다면 모두 삭제하고 tensorflow-cpu==2.10 버전으로
다시 다운 받도록 하자.
2. 설치 확인
1) gpu 인식 확인
# 1. gpu 사용 가능 여부 확인 import tensorflow as tf print(tf.config.list_physical_devices('GPU')) # 2. gpu 인식 여부 확인 from tensorflow.python.client import device_lib device_lib.list_local_devices()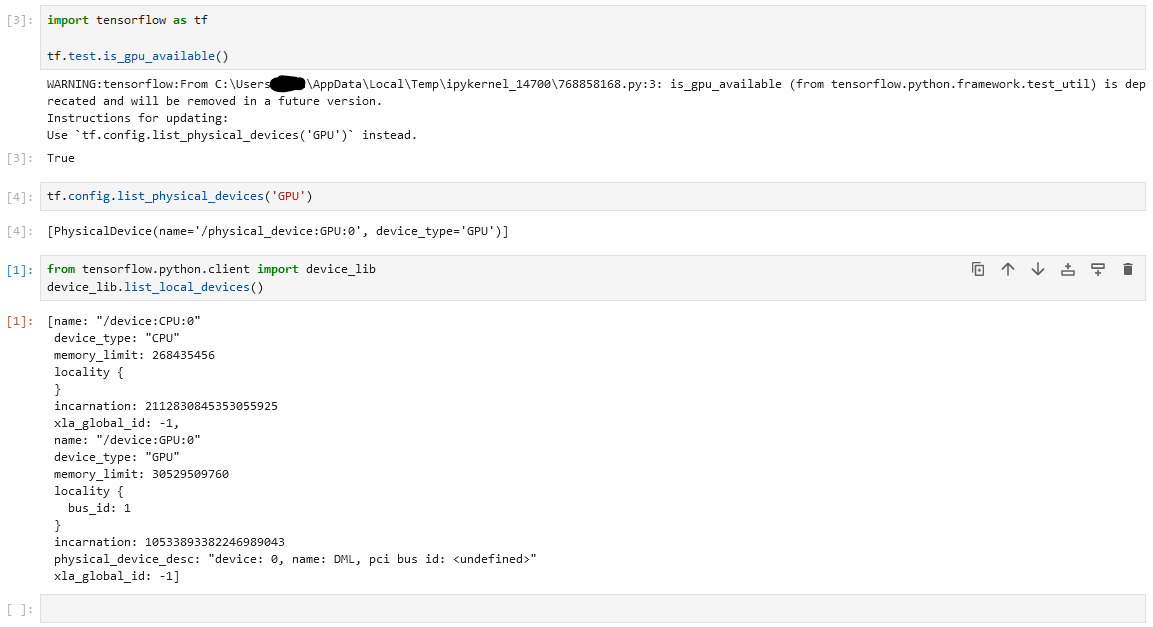
Tensorflow+DirectML GPU 인식 확인 결과 device_lib.list_local_devices() 코드 실행 시, 하단처럼 device_type : "GPU" 가 정상적으로 출력되어야 합니다.
2) Pytorch GPU 동작 확인
import torch import torch_directml dml = torch_directml.device() tensor1 = torch.tensor([1]).to(dml) tensor2 = torch.tensor([2]).to(dml) dml_algebra = tensor1 + tensor2 dml_algebra.item()gpu에 tensor를 할당해 연산 시키는 코드입니다. 결과창에 3이 나온다면 정상적으로 인식되고 작동하는 것 입니다.
3. 윈도우 작업관리자에서 GPU 연산 확인하는 방법

GPU - compute 0 gpu 성능창으로 이동해서 그래프 이름 선택 - Compute 0 으로 변경

(좌) GPU를 사용하여 학습 시, 변화 (우) 학습하지 않을 때 좌측은 GPU를 사용하는 학습을 진행 할 때, Compute 0의 사용량이 늘어남을 확인 할 수 있다.
우측은 학습이 끝나고 GPU 연산을 하지 않을 때로, 사용률이 올라가지 않는다.
4. 간단한 학습으로 GPU 사용 시와, CPU 사용 시 성능 비교
4.1) CPU 사용 코드 + 사용 시,
*알림* 위 순서대로 설치 시, Tensorflow를 통해 학습을 진행 할 때, 자동적으로 GPU를 할당하여 사용함.
따라서, 본 실험을 위해 CPU 만을 사용하기 위해 동일한 버전의 tensorflow(2.10)가 설치된 가상환경을 만들어 진행함.
[실험 코드]
#only-cpu ML import tensorflow as tf import time # GPU 사용 확인 if tf.test.is_gpu_available(): print("GPU 사용 가능") else: print("GPU 사용 불가능") # MNIST 데이터셋 다운로드 (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() # 데이터 전처리 x_train = x_train.reshape(x_train.shape[0], 784) x_test = x_test.reshape(x_test.shape[0], 784) x_train = x_train / 255.0 x_test = x_test / 255.0 # 모델 생성 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(784,)), tf.keras.layers.Dense(1024, activation="relu"), tf.keras.layers.Dense(1024, activation="relu"), tf.keras.layers.Dense(10, activation="softmax") ]) # 컴파일 model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) # CPU 학습 start_time = time.time() model.fit(x_train, y_train, epochs=30) end_time = time.time() cpu_time = end_time - start_time # 학습 결과 출력 print("CPU 학습 시간:", cpu_time) # 테스트 결과 출력 score = model.evaluate(x_test, y_test, verbose=0) print("CPU 테스트 정확도:", score[1])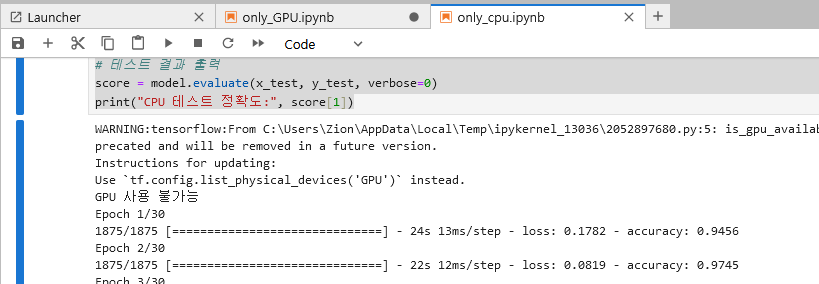
DirectML이 없으므로 GPU 사용 불가능 
CPU 학습 시간 
작업관리자 - CPU 사용 4.2) GPU 사용 코드 + 사용 시,
Tensorflow-cpu (2.10) + DirectML
#GPU Used import tensorflow as tf import time # GPU 사용 확인 if tf.test.is_gpu_available(): print("GPU 사용 가능") else: print("GPU 사용 불가능") # MNIST 데이터셋 다운로드 (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() # 데이터 전처리 x_train = x_train.reshape(x_train.shape[0], 784) x_test = x_test.reshape(x_test.shape[0], 784) x_train = x_train / 255.0 x_test = x_test / 255.0 # GPU 학습 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(784,)), tf.keras.layers.Dense(1024, activation="relu"), tf.keras.layers.Dense(1024, activation="relu"), tf.keras.layers.Dense(10, activation="softmax") ]) # GPU 설정 with tf.device("GPU:0"): model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) # GPU 학습 start_time = time.time() model.fit(x_train, y_train, epochs=30) end_time = time.time() gpu_time = end_time - start_time # 학습 결과 출력 print("GPU 학습 시간:", gpu_time) # GPU 테스트 결과 출력 with tf.device("GPU:0"): score = model.evaluate(x_test, y_test, verbose=0) print("GPU 테스트 정확도:", score[1])결과창에 GPU 사용 가능이 출력

DirectML + Tensorflow 로 GPU를 사용 
GPU 학습 시간 
작업관리자 - GPU 사용 4.2) 최종 비교
CPU 학습 시간 : 674.54 (s)
GPU 학습 시간 : 333.26 (s)
CPU 학습 정확도 : 0.9817
GPU 학습 정확도 : 0.9793
결과적으로 CPU 대비 GPU 학습 시, 시간은 50.59% 단축
정확도는 0.24% 차이로 CPU의 정확도가 높으나, 비교 실험을 한 번 만 했기 때문에 오차 범위로 판단했습니다.
비교 실험 횟수를 늘리면 정확도는 큰 차이가 나지 않을 것 같고, 학습 시간은 대부분 50% 내외로 차이가 날 듯 합니다.
5. 결론
AMD 그래픽 카드도 윈도우에서 native 하게 머신러닝을 돌리는게 가능합니다.
다만, ROCm은 아쉽긴하네요.
DirectML은 MicroSoft에서 관리 및 배포하고 있습니다.자세한건 공식 문서와 github 링크를 남기니, 참고하시길 바랍니다.
https://learn.microsoft.com/ko-kr/windows/ai/directml/gpu-tensorflow-plugin
https://github.com/microsoft/DirectML
[사용 후기]
1. AMD 그래픽카드(Radeon)으로 리눅스가 아닌 윈도우에서 Native하게 ML하는 것이 가능해졌다.
2. 다만, Tensorflow 버전은 2.10으로 고정적이다.
3. DirectML설치 후, Tensorflow는 코드 실행 시, 자동으로 그래픽카드를 잡아서 일을 시킨다.
4. 다중 그래픽카드 사용 시, 모두 사용은 불가능한듯 하다.
(하나의 모델을 돌리기 위해 여러 개의 그래픽카드 사용 불가, 여러 모델에 각 각 그래픽카드 할당 가능)5. 최근 AMD가 AI 쪽으로 관심을 가지고 있는듯 하나, 지원이 아직 부족하다.
(ROCm 와 AI 관련 질문에 답을 사용자가 해줌..)'ML(머신 러닝) > Windows' 카테고리의 다른 글
[DL][Windows] 윈도우 텐서플로우 (TensorFlow) GPU 인식 문제 (2) 2023.12.07 [DL][Windows11] YOLOv3 커스텀 데이터셋 만들기 (0) 2023.09.22 [DL][Windows11] YOLOv3 물체 검출 학습 (0) 2023.09.22 [DL][Windows 11] 윈도우 파이토치 (PyTorch) 설치 (0) 2023.06.07 [DL][Windows 11] 윈도우 텐서플로우 (TensorFlow) 설치 (0) 2023.06.02
